












2020云数据仓库基准:Redshift, Snowflake, Presto和BigQuery

如果你对下载这份报告感兴趣,你可以这样做在这里.
在过去的两年中,主要的云数据仓库在性能上一直不相上下。Redshift和BigQuery的用户体验都与Snowflake更加相似。市场正在围绕两个关键原则聚合:计算和存储分离,以及可以“峰值”处理间歇性工作负载的固定费率定价。
Fivetran是一个数据管道,将应用程序、数据库和文件存储的数据同步到我们客户的数据仓库。我们最常被问到的问题是,“我应该选择什么数据仓库?”为了更好地回答这个问题,我们执行了一个基准测试,比较了四个最流行的数据仓库的速度和成本:
亚马逊红移
雪花
转眼间
谷歌BigQuery
基准测试都是关于做出选择:我将使用什么样的数据?多少钱?什么样的查询?如何做出这些选择非常重要:改变数据的形状或查询的结构,最快的仓库可能会变得最慢。我们试图以一种典型的方式做出这些选择Fivetran这样,结果将对使用Fivetran的公司有用。
一个典型的Fivetran用户可以将Salesforce、JIRA、Marketo、Adwords和他们的Oracle生产数据库同步到数据仓库中。这些数据源并没有那么大:一个典型的数据源将包含数十到数百gb。它们很复杂:它们在规范化模式中包含数百个表,我们的客户编写复杂的SQL查询来总结这些数据。
这个基准测试的源代码可以在https://github.com/fivetran/benchmark.
我们查询了什么数据?
我们生成了1TB规模的TPC-DS[1]数据集。TPC-DS在雪花模式中有24个表;这些表格代表了虚拟零售商的网络、目录和商店销售。最大的事实表有40亿行[2]。
我们运行了哪些查询?
我们在2 - 9月运行了99个TPC-DS查询[3]。2020股。这些查询很复杂:它们有大量的连接、聚合和子查询。我们只运行每个查询一次,以防止数据仓库缓存以前的结果。
我们如何配置仓库?
我们将每个仓库设置为100GB和1TB规模的小型和大型配置:
| 配置 | 成本/小时[4] | |
|---|---|---|
| 红移 | 5 x ra3.4xlarge | 16.30美元 |
| 雪花[5] | 大 | 16.00美元 |
| 转眼间[6] | 4 x n2-highmem-32 | 8.02美元 |
| BigQuery[7] | 600年固定费率时段 | 16.44美元 |
我们是如何调整仓库的?
这些数据仓库都提供了诸如排序键、集群键和日期分区等高级功能。在这个基准测试[7]中,我们选择不使用这些特性。我们在Redshift中应用了列压缩编码;Snowflake和BigQuery自动应用压缩;Presto使用了HDFS中的ORC文件,这是一种压缩格式
结果
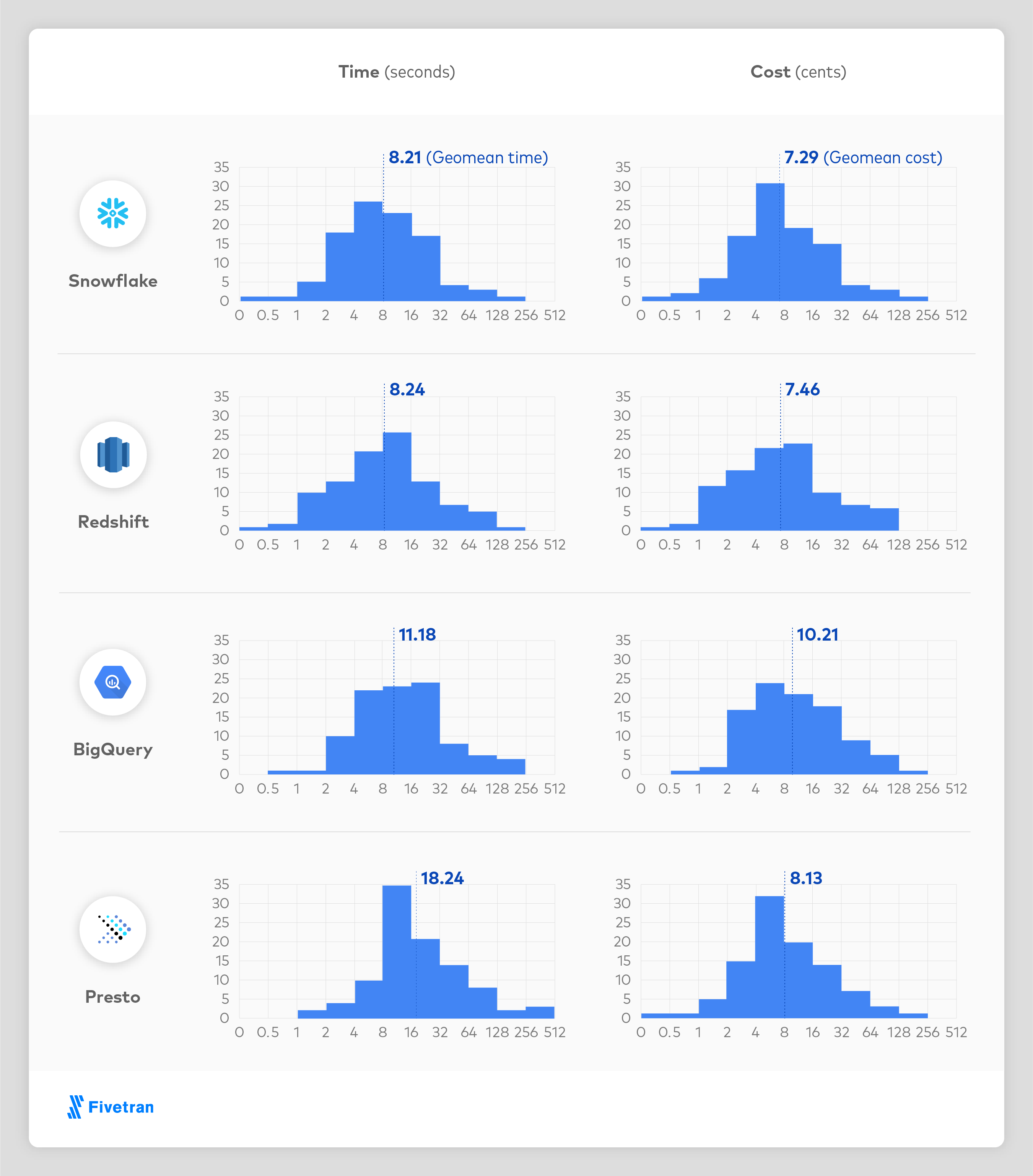
所有仓库都有极好的执行速度,适合于特别的交互式查询。为了计算成本,我们将运行时乘以配置[8]的每秒成本。
仓库有何不同?
每个仓库都有独特的用户体验和定价模型。我们可以把它们放在一个光谱上:
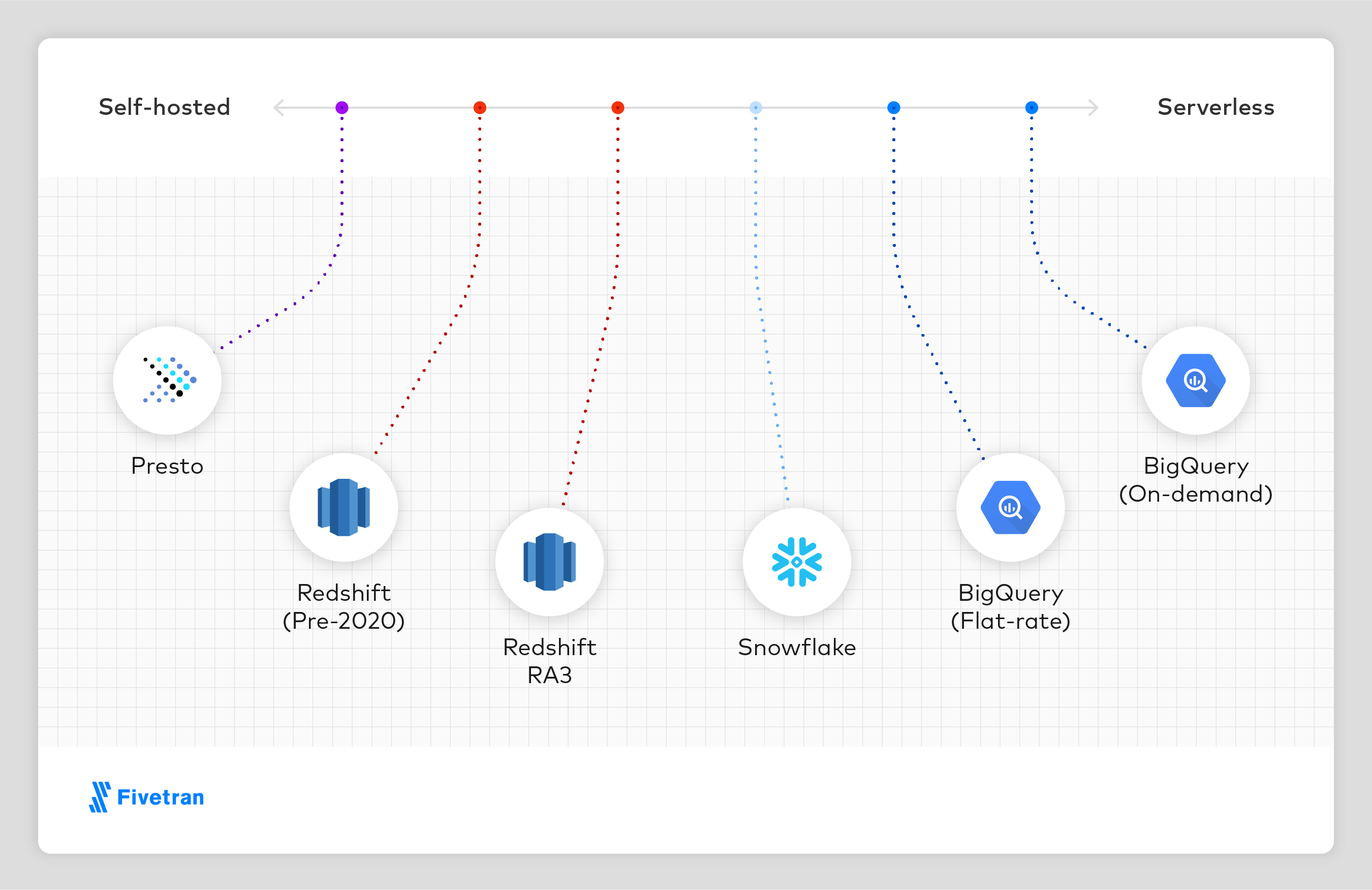
在这个范围的“自托管”一端是Presto,用户负责提供服务器和Presto集群的详细配置。Presto是开源的,不像这个基准测试中的其他商业系统,这对一些用户来说很重要。
Pre-RA3 Redshift的管理更加全面,但仍然需要用户配置具有固定数量的内存、计算和存储的单个计算集群。Redshift RA3通过将计算与存储分离,使Redshift更接近Snowflake的用户体验。
Snowflake是一种几乎没有服务器的体验:用户只配置计算集群的大小和数量。每个计算集群看到相同的数据,可以在几秒钟内创建和删除计算集群。雪花有几个定价层与不同特征相联系的;我们的计算是基于最便宜的“标准”。如果您希望在工作负载中使用“企业”或“业务关键”,那么您的成本将增加1.5倍或2倍。
BigQuery固定速率类似于Snowflake,除了没有计算集群的概念,只有可配置的“计算槽”数量。BigQuery按需查询是一个纯粹的无服务器模型,用户一次提交一个查询,并为每个查询付费。随需应变模式的成本可能高得多,也可能低得多,这取决于工作负载的性质。在固定费率模式下,24/7利用计算能力的“稳定”工作负载要便宜得多。在按需模式下,包含周期性的大型查询和长时间的空闲或较低利用率的“尖尖”工作负载要便宜得多。
为什么我们的结果与以前的基准不同?
Gigaom云数据仓库性能基准
2019年4月,Gigaom在BigQuery、Redshift、Snowflake和Azure SQL数据仓库(Azure Synapse)上运行了一个版本的TPC-DS查询。这个基准测试由微软赞助。他们使用了30多倍的数据(30 TB vs 1 TB)。他们为不同的系统配置了不同大小的集群,观察到的运行时比我们慢得多:
| 系统 | 集群成本 | Geomean时间 |
|---|---|---|
| SQL Azure DW | 181美元/小时 | 15.60 |
| 红移 | 144美元/小时 | 18.45 |
| 雪花 | 128美元/小时 | 28.40 |
| BigQuery | 55美元/小时 | 101.22 |
考虑到它们的星团是我们的5 - 10倍,它们的数据是我们的30倍,它们观察到的性能如此之慢,这很奇怪。
亚马逊的Redshift vs. BigQuery基准
2016年10月,亚马逊在BigQuery和Redshift上运行了一个版本的TPC-DS查询。亚马逊报告称Redshift的速度是BigQuery的6倍,BigQuery的执行时间通常超过1分钟。他们的基准与我们的主要区别是:
他们使用了10倍大的数据集(10TB vs 1TB)和2倍大的Redshift星团(38.40美元/小时vs 19.20美元/小时)。
他们使用sort和dist键调优了仓库,而我们没有。
2016年10月,BigQuery Standard-SQL仍处于测试阶段;到2018年底,当我们运行这个基准测试时,它可能会变得更快。
对于那些声称自己的产品是最好的厂商的基准测试,我们应该持保留态度。亚马逊的博客文章中有很多细节没有说明。例如,他们使用了一个巨大的Redshift集群——他们是否将所有的内存分配给一个用户以使这个基准测试超级快地完成,即使这不是一个现实的配置?我们不知道。如果AWS能够发布再现基准测试所需的代码,那就太好了,这样我们就可以评估它的可行性。
Periscope的Redshift vs. Snowflake vs. BigQuery基准
同样在2016年10月,Periscope Data比较了Redshift、Snowflake和BigQuery,使用了三个小时聚合查询的变体,将一个10亿行事实表与一个小维度表连接起来。他们发现Redshift和BigQuery的速度差不多,但是Snowflake要慢两倍。他们的基准与我们的主要区别是:
他们多次运行相同的查询,消除了Redshift缓慢的编译时间。
他们的查询比我们的TPC-DS查询简单得多。
使用“简单”查询进行基准测试的问题是,每个仓库在这个测试中都表现得很好;不管Snowflake做一个简单的查询快还是Redshift做一个非常非常快的简单查询。重要的是您是否能够以足够快的速度完成这些困难的查询。
Periscope也比较了成本,但他们使用了一种有点不同的方法来计算每次查询的成本。和我们一样,他们查看客户的实际使用数据,但不是使用空闲时间百分比,而是查看每小时的查询数量。他们认为大多数(但不是所有)Periscope客户会发现Redshift更便宜,但这并不是很大的区别。
Mark Litwintschik的11亿次出租车出行基准
Mark Litwintshik在2016年4月和2016年6月对BigQuery和Redshift进行了基准测试。他对一个包含11亿行的表运行了4个简单的查询。他发现BigQuery的速度和一个比我们大2倍的红移星团差不多(41美元/小时)。两个仓库都在1-3秒内完成了查询,所以这可能代表了“性能下限”:即使是最简单的查询也有最小的执行时间。
结论
这些仓库都具有极好的价格和性能。我们不应该对它们的相似之处感到惊讶:创建快速柱状数据仓库的基本技术已经广为人知C-Store纸于2005年出版。这些数据仓库无疑使用了标准的性能技巧:柱状存储、基于成本的查询规划、流水线执行和即时编译。我们应该怀疑任何宣称一个数据仓库比另一个数据仓库快得多的基准。
仓库之间最重要的区别在于它们的设计选择造成的质量差异:一些仓库强调可调性,另一些强调易用性。如果您正在评估数据仓库,那么您应该演示多个系统,并选择一个适合您的平衡点。
关于Fivetran: Fivetran是自动数据集成的领导者,提供随时可用的连接器,随着模式和api的变化自动适应,确保对数据的一致、可靠访问。Fivetran通过不断地将数据从源应用程序同步到任何目的地,提高了数据驱动决策的准确性,使分析师能够使用最新的可能数据。为了加速分析,Fivetran支持仓库内的转换并交付特定于源的分析模板。了解更多关于随时间变化的数据集成www.miaplace.com,或开始免费试用www.miaplace.com/signup.
笔记
[1] TPC-DS是一种用于数据仓库的行业标准基准测试。即使我们使用了TPC-DS数据和查询,这个基准测试也不是一个正式的TPC-DS基准测试,因为我们只使用了一个尺度,我们对查询进行了轻微的修改,并且我们没有调优数据仓库或生成查询的替代版本。
[2]以数据仓库的标准来看,这是一个小的规模,但大多数Fivetran用户感兴趣的数据源,如Salesforce或MySQL,它们有复杂的模式,但大小适中。
我们必须稍微修改查询以使它们能在所有仓库中运行。我们所做的修改很小,主要是更改类型名。我们使用的是BigQuery标准sql,而不是遗留sql。
为了计算每个查询的成本,我们假设每个仓库有50%的时间在使用中。
雪花成本基于AWS的“标准”定价。如果您使用“企业”或“关键业务”等更高级别,您的成本将增加1.5倍或2倍。
[6] Presto是一个开源的查询引擎,所以在这个基准测试中它并不能真正与商业数据仓库相媲美。但它有潜力成为这个领域中一个重要的开源替代品。我们使用半。329的的亮光转眼间的分布。成本基于谷歌Cloud上实例的按需成本。
[7] BigQuery是一个纯粹的共享资源查询服务,所以没有等效的“配置”;您只需将查询发送给BigQuery,它就会将结果返回给您。
[8]如果您知道将在您的仓库上运行什么类型的查询,那么您可以使用这些特性来调优您的表,并更快地执行特定的查询。然而,典型的Fivetran用户在他们的仓库上运行各种不可预测的查询,因此总会有很多查询不能从调优中受益。
我们假设真实世界的数据仓库有50%的时间是空闲的,所以我们将基本每秒成本乘以2。